您现在的位置是:首页 > IT基础架构 > 软件与服务 >
基于元数据的语义识别搜索方法的研究与实现
摘要本文设计开发了一种基于元数据的网络搜索语义识别算法,并成功应用于中国可持续发展信息共享系统中,建立基于可持续发展元数据的搜索引擎,对用户的不同需求提供不同的元数据搜索方式,最终根据可持续发展共享数据与元数据的映射关系,实现由基于数据分类存储模式的数据共享...
1 引 言
近几年,Intemet的资源迅速增长,使web发展成为包含多种信息资源、站点遍布全球的海量信息服务网络。同时,也有越来越多的机构、团体和个人在Intemet上用搜索引擎查询信息。对于一个门户网站来说,提供给用户搜索服务,是吸引用户访问网站的重要手段。因此搜索技术是当前网络领域中最为热门的研究领域,搜索引擎的好坏在很大程度上决定了用户使用网络资源的效率高低。搜索引擎的效率主要是取决于对于用户输入要求的解析与识别,因此需要能够对用户输入的信息进行语义解析,从而准确有效地对用户意图进行识别、解析与理解。并为用户返回最为合适的搜索结果,如何更好地解决上述问题是搜索引擎急需解决的关键问题。中国可持续发展信息共享网作为我国可持续发展领域的主要门户网站,实现了对外提供可持续发展数据信息共享与服务,有效地促进了我国可持续发展领域的数据交换与信息共享。然而网站的持续运行,数据量不断增加,数据服务能力也不断提升,如何在浩如煳海的可持续发展数据仓库中方便快捷地查询用户需要的数据信息是系统进一步发展所急需解决的问题。
本文针对上述问题,设计开发了一种基于元数据的网络搜索语言模式识别算法,通过元数据作为用户语义检索的解析器,以解析用户各种数据与信息的请求。该方法成功应用于中国可持续发展信息共享系统中,建立基于可持续发展元数据的搜索引擎,对用户的不同需求提供不同的元数据搜索方式,最终根据可持续发展共享数据与元数据的映射关系,实现由基于数据分类存储模式的共享服务转变为以元数据搜索为驱动的数据共享服务模式,极大提高了搜索引擎的有效搜索能力,为用户提供了高效的可持续发展搜索引擎。
2 元数据与可持续发展元数据结构
2.1 元数据
元数据是由数据生产者提供的说明数据内容、质量、状况以及如何获取数据的结构化的摘要信息。由于Internet上地理信息资源具有海量性、分布性、异构性等特点,为了使数据用户能够从生产者那里获取快捷、安全、有效、全面的数据服务,需要建立元数据为用户提供数据来源、投影方式、坐标系统、作业方式、作业时间、作业人员、数据质量、编码方案、采用的标准等一系列描述信息。
元数据最重要的作用在于它提供目录数据,能使用户方便地找到数据。即资源发现(Resource Discovery)功能,或者说导航(Navigation)功能、目录服务(Catalog Service)功能。
2.2 中国可持续发展元数据
为了便于用户了解、访问与获取可持续发展网提供的各种数据资源,可持续发展信息共享系统的设计人员制定了中国可持续发展信息共享元数据标准,并在此标准支撑下,形成了可持续发展元数据集。中国可持续发展信息共享元数据标准规定把元数据分为两级。一级元数据是唯一标识一个数据集(数据集、数据集系列、要素和属性)所需要的最少的元数据实体和元素。二级是建立完整的数据集(数据集、数据集系列、要素和属性)文档所需要的核心元数据实体和元素。其中,一级元数据只包含编目信息。任何数据集(数据集、数据集系列、要素和属性)一般都应有一级元数据文件。二级元数据节点属性不具有这样的惟一性和必要性,因此,在语义搜索的实现中,不涉及二级节点属性。如E所述,基于可持续发展元数据标准形成的元数据XML交换文件,采用XML标示元数据标准中规定的各层级节点。举例来说,mdFileID(数据集中文全称)节点为一级元数据节点,也是可持续发展元数据节点中必须存在的节点之一。
3 元数据的搜索引擎设计与实现
可持续发展信息共享系统中数据的快速查询、定位与导航都是一个需要重点解决的问题。由于可持续发展集中共享数据都有其对应的元数据说明文件。因此以元数据为导向,作为用户搜索语言的语义解析器,对用户输入信息进行解析,并通过转为元数据的搜索以及数据与元数据的一一对应关系.就能对数据是否能满足用户需要做出正确的判断,最终为用户找到所需要的真实数据提供支撑。
3.1 传统的基于数据库的元数据语义搜索方法的缺陷
过去由于思路和技术的局限性,要实现针对XML模式的全文检索方式是一个难题。为了实现针对元数据的查询检索,系统采取了借助数据库搜索技术的方法来实现元数据的查询。首先分析用户查询元数据时最感兴趣且最容易使用的元数据节点,将这些节点作为数据表字段,提取每个元数据中该节点的属性值作为字段值。同时将元数据文件采用大文件的方式直接存储在数据库中,提供网络发布,便于用户查看。用这种方式,也可以满足一部分用户对于数据检索的需求,但是很明显,这种方式存在很多不足之处。
首先,在提取元数据信息时,不能保证系统提取的字段能满足用户的查询需要。其次,从XML文档中提取信息保存到数据库中的过程不但需要代码实现,还必然需要人工配合,无形中浪费了资源,影响了效率。第三,数据库搜索本身有很多局限性。比如,数据库检索的效率非常地下,会消耗大量硬件资源,无法完成全文检索(可以用SQL的单子索引功能最简单的完成索引功能实现低级的全文索引),无法高亮显示检索词,也不能对结果集按照相关性进行结果排序。
根据上述原因,必然需要改变以前这种基于数据库的搜索方式,采用新的模式实现中国可持续发展数据搜索引擎。本文提出采用基于元数据文件的语义检索方式实现搜索引擎,该模式如图1所示:
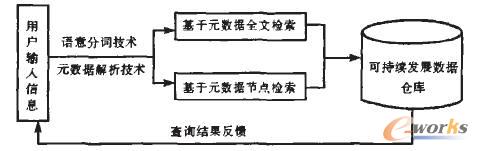
图1 基于元数据的可持续发展语义检索模式
3.2 元数据文件搜索引擎的实现
如3.1所述,过去为了达到搜索元数据信息的目的,我们把以文件形式存储的元数据文件人工提取出部分信息转换到数据库中储存,这种方式存在很多弊端。而现在结合基于文件的语义搜索方法,可以实现直接对元数据文件进行搜索,从而达到查找数据的最终目的。搜索引擎的设计考虑到用户有不同需求和不同查询条件,因此为元数据的搜索引擎提供两种入口:全文搜索和针对元数据节点元素的搜索。
全文搜索是一种对用户最为方便的搜索方式,对于用户而言,只要知道关于这个数据的任何一点信息,都能通过全文搜索引擎查找到需要的数据。元数据全文搜索引肇的建立就是利用全文搜索的这一特性,方便用户在海量的可持续发展信息共享数据中根据其无数据的描述信息来快速查找需求的数据。简单的查询通常是文本查询,在元数据的每个文档中搜索每个(或所有)查询词。但是如果单纯只是打开并扫描每个文档,寻找每个查询词,那会因为处理杏询时打开每个文档并搜索查询词而浪费不少时间,影响搜索效率。
因此,元数据的全文搜索的实现方法是,根据XML文件格式的标准,采用信息获取技术提出每个文档中的真实信息来建立索引,并用一种便于检索的方法保存索引。那么处理查询时就不用扫描每个文档了,而是采用反向索引相互比较元数据,并选择与查询最有关联的元数据。这样,全文搜索就能以文本形式的元数据为主要处理对象,基于全文标引,使用自然语言来进行检索。
系统采用的检索算法属于索引检索,即用空间换取时间,对要检索的文件、字符流进行全文索引。在检索的时候对索引进行快速的检索,得到检索位置,这个位置记录检索词出现的文件路径或者某个关键词。因为对于每一个切分出来的词组项,这种索引可以列出包含它的文档。这就是文档与项自然联系的倒置,也就是倒排索引。
全文搜索的实现过程有以下几个主要关键步骤:
1)从元数据文档存储区读取文档信息。
2)利用筛选器过滤元数据文档中的格式信息和非文字信息,生成文字串和属性/值对,并把它传递给索引引擎,如图2即是相对于上文中所示的可持续发展元数据文件格式进行了筛选,过滤了无用信息后得到的元数据关键词。

图2 读取的XML关键词字符串
3)对提取的字符串进行反向索引。也就是记录包含搜索词的文档的信息、出现次数以及搜索闻在文档中的相关位置。就是说将习惯思维的对应关系:“文件号”对“文件中所有关键词”,利用倒排索引把这个关系倒过来,变成:“关键词”对“拥有该关键同的所有文件号”,即某个查询词在某些文件中出现过。反向索引可以应用统计和概率公式,以便快速计算文档的相关性。对2)中得到的字符串进行分词后的效果如图3所示。除了记录关键词在哪些元数据文件中出现还不够,我们还需要知道关键词在出现次数和出现的位置,这样就可以在显示查询结果时对于关键词进行高亮(例如,关键词字体变红或者加粗)处理,并且节约索引空间,提高查询效率。关键词的索引结果如表1所示(假设有两个编号为1和2的元数据文件):表1说明“中国”这个关键词在元数据文件2中出现过3次,出现位置分别为第5,16和22个关键词。

图3 对字符串分词
表1 倒排索引的索引结构

(本文不涉密)
责任编辑:
上一篇:市场研究中的多变量分析技术
特别推荐





 |
站点信息
- 运营主体:中国信息化周报
- 商务合作:赵瑞华 010-88559646
- 微信公众号:扫描二维码,关注我们
