您现在的位置是:首页 > IT基础架构 > 软件与服务 >
基于统计数据的OLAP数据挖掘技术
摘要本文主要探究了在OLAP对数据灵活访问优势的基础之上,适当减少分析过程中的人工于预,提高OLAP分析的自动性,将分析的灵活性和自动性有机地结合起来,使OLAP技术更能够适应实际分析的需要。 ...
一、概 述
数据挖掘是90年代中后期兴起的一门跨学科的综合研究领域,它集计算机机器学习、统计学、数据库管理、数据仓库、可视化、并行计算、决策支持为一体,利用数据库、数据仓库技术存储和管理数据,利用机器学习和统计学方法分析数据,旨在发现大量复杂数据中蕴含的有价值的知识和信息。目前,随着数据挖掘应用的不断开展以及客观现实对数据分析需求的不断增长,人们越来越认识到数据挖掘的重要性和必要性。_
数据挖掘通过对数据的总结、分类、聚类、关联等分析,实现对数据内在结构特征的理解和对未知数据的预测。其中,数据总结是在数据挖掘初期阶段进行的基础性分析,是其他深层次数据分析的出发点。数据挖掘所采用的技术一般有OLAP(联机分析处理)、近邻分析、聚类分析、决策树分析、神经网络分析、推理规则等。其中,OLAP技术是目前数据仓库和数据挖掘软件,如:SAS公司的Enterprise Miner、Business Object公司的决策支持系统Business Object、Microsoft的SQL Server,以及IBM公司的决策分析工具IntellisentMiner等软件中最常见的一种分析技术。
数据总结的目的是实现对数据的“浓缩”和“泛化”,它能够使人们在不同的层次和不同的角度,对数据有一个既概括又详尽的理解和把握。对数据的总结分析一般可以利用两种技术实现:一种是采用传统的描述统计分析方法,通过计算数据的均值、方差、峰度、偏度等基本描述指标,结合各类统计图形展现数据的总体分布特征;另一类种是采用OLAP联机分析技术。OLAP是一种联机的多维数据分析方法。联机体现在:分析过程需要用户的积极参与,并动态地提出分析要求、选择分析算法,实现对数据由浅至深的探索性分析;多维体现在:它将数据仓库中数据的各种属性,比如产品的分类、地域、时间、客户等等都看作是描述数据属性的“维”;某维上不同层次的分类形成粗细不同的“粒度”,如:对地域这个属性,可以按行政区划分,也可以按自然的地理区域划分,前者的划分粒度较后者细。于是,数据值便可以看作是以维为坐标轴、以粒度为坐标刻度的超立方上的点。OLAP能够以不同的维和不同的粒度,提取超立方中的数据并对其进行各种分析,其中最常见的是实现不同层次和不同角度的数据总结分析。
随着OLAP技术的普遍应用,人们对它的分析能力提出了新的要求,即希望:在OLAP对数据灵活访问优势的基础之上,适当减少分析过程中的人工于预,提高OLAP分析的自动性,将分析的灵活性和自动性有机地结合起来,使OLAP技术更能够适应实际分析的需要。正是这种新要求的出现,给OLAP技术提出了新的挑战。例如:在数据总结分析中,正是由于有人工干预,OLAP技术可以只负责数据的汇总,而一般无须考虑数据在该维或该粒度上数据总结的合理性,不考虑这种分析是否有实际意义。但如果缺少了人工的干预,情况就会复杂得多,尤其体现在OLAP技术对统计数据的多维分析方面。本文希望对这方面问题进行一些探索研究。
二、统计数据OLAP分析的问题
统计数据是OLAP分析对象中一个极为重要而特殊的群体。这里谈论的统计数据(或称统计指标)特指那些由个体数据(或称原始数据)经过汇总所生成的总体数据(或汇总数据),如:“1998年北京市高等院校从事社科活动的教授人数为2218人”就是一个典型的统计数据。通过观察可以看出:这类统计数据由指标名和指标值两个部分组。如上例中,1998年北京市高等院校从事社科活动的教授人数就是指标名,2218为指标值。从OLAP角度看,数据超立方中的维体现在统计数据的指标名上,如上例中:年份、地区、职称等都是对指标值属性的描述,都可以看成OLAP的维。维的粒度体现在指标名的具体分类上,如上例中地区维的粒度是行政区划等。统计数据中这样的维还可以列举出很多,如:不同专业、不同性别、不同职业、不同文化程度等等。同时,根据不同的统计分类也可以形成粗细不同的粒度。
利用OLAP技术对统计数据的总结分析是极为普遍的。如上例中:在地区维上进行OLAP汇总就可以得到1998年全国从事社科活动的教授人数;在职称维上进行分析,就可以得到1998年北京市从事社科活动的总人数;在地区和职称两维上同时进行分析,就可以得到1998年全国从事社科活动的总人数。
因此,利用OLAP技术对统计数据进行总结分析就是要根据实际分析的需要,选择指标名中合适的维,对指标值进行基本汇总。选择合适的维,在统计数据的OLAP分析中是极为关键的,它需要对统计数据的类型、统计指标的分类有较为明确的理解。否则,数据总结的结果很可能是不符合逻辑或没有意义的。可以用下面两个简单的例子来说明这些问题。
例1:对某大学某系在校硕士生人数进行OLAP分析。这里假设该系从1997年开始招生,学制为三年,有两个研究方向。现收集到的是以下关于各年各研究方向在读学生人数的统计数据:
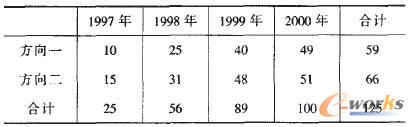
可以看出,上表的统计数据是二维的,分别是研究方向和时间(年份),现在利用OLAP技术对它们分别按研究方向和年份进行数据总结。研究方向维的分析,只需在研究方向维仁计算指标值的总和(如:10+15=25),便可得到各年两个方向在读学生人数的分布情况。但时间(年份)维的分析,就不能简单地将各年的指标值求和(如:10+25+40+49=124),否则会得到一个不符合逻辑的分析结果。以研究方向一为例,正确的做法应是:10+(25-10)+(40一25)+(49-(40-10))=59,这里需要考虑学制满三年的学生要离开学校的情况。因此,本例中对统计数据进行OLAP分析,并不是所有的维都可以进行数据总结,应有一定的限制条件,否则便会得出错误的结论。
这里,时间维出现了错误,究其原因是由时间序列中统计指标的不同类型造成的。众所周知,在时间序列中,统计指标可以分成时期指标和时点指标。时期指标反映的是某事物在一段时间内的活动总量,如:国内总产值、月交通事故死亡人数等。时期指标中各观察值在时间轴上是可以直接相加的,用于反映现象在更长一段时期内的活动总量。时点指标反映的是某事物在某一瞬间时点上的总量,如:年末总人口数、月末再就业人数等。由于时点指标是在某一时间点上统计得到的,因此,时点指标中各观察值在时间轴上通常是不能相加的。由于例1中统计指标是一个时点指标,所以它在时间(年份)维上相加是没有意义的,但在研究方向维上是可以相加的。
例2:仍然用例1中的数据,但假设允许一个学生同时攻读两个研究方向,仍利用OLAP技术对数据分别按研究方向和年份进行数据总结。研究方向维上的分析,与例1不同的是,由于一个学生可以同时攻读两个研究方向。如果将每个研究方向看作一个集合,那么,这两个集合中会存在相同的学生记录,简单计算总和(如:10+15),必然出现数据重复计算的问题,其结果就不能准确地反映各年在读学生的人数情况。在时间(年份)维上的分析,与例1相同,指标为时点指标,不能在时间轴上加总。
三、统计数据OLAP分析的约束条件和技术保障
通过上面两个例子不难看出,利用OLAP技术对统计数据进行自动的多维汇总时,应考虑到一些必要的约束条件,它们是统计数据OLAP分析正确性的保证。总结起来,这些约束条件大致有两个方面:
第一,统计指标的类型
OLAP在时间维上的数据总结,应考虑统计数据是时期指标还是时点指标。对于时点指标,OLAP无法在时间维上直接进行数据总结分析。另外,还应注意到统计指标的含义。如:如果统计数据为平均值、中位数、方差等描述统计量,那么对这些数据的总结分析就相对比较复杂,简单地利用OLAP技术就会出现错误。
第二,统计指标的分类
利用OLAP技术在各维方向上进行数据总结,应保证各维上统计指标名形成的分类不重部不漏。不重指各分类子集的交集应为空集,每个个体数据应唯一从属于一个子集。不漏指所有分类子集的并集应为全集,每个个体数据必须属于某个分类子集。这点与统计学中的统计分组原则是相同均。
为使OLAP技术能够自动且正确地实施于统计数据的总结分析,应在具体实现技术方面加以研究。目前,国际仁解决这类问题大多从研究如何存储统计数据和统计数据语义方面入手,将上述各约束条件体现在统计数据的语义模型中。当OLAP分析实施于这样的统计数据模型上时,系统会自动给出正确或错误的提示信息。统计数据的存储模式仍然可以借鉴存储个体数据的超立方数据模式,但还应在元数据中加入关于统计数据语义的描述信息。大致有以下三个方面:
1.基础数据库语义的描述
统计数据是由个体数据汇总得到的,个体数据一般都存储在以个体数据为基本记录单元的基础数据库中。为准确表达统计数据的语义,应将原来基础数据库中相关数据项的含义描述清楚。其中包括:
(1)基础数据库中关键字段名和其他相关数据项内容
(2)基础数据的必要解释和说明
例如:例1中的统计数据是由基础学生数据库中的个体数据中派生出来的,对它的描述可以为。①关键字段为学号;其他相关数据项为:“入学年份”(字符类型)、“研究方向”(字符类型)②学制三年;每个学生只能攻读一个研究方向;1997年开始招生。
2.各统计数据含义的描述
这里主要是对上述第一方面约束条件的反应,包括:
(1)指标名称、使用的函数、数据类型、取值范围等
(2)指标类型
(3)对该指标可进行哪些函数运算
例如,例1中的统计数据含义可以描述为:①在校人数、根据关键字段利用计数函数得到、正整数、取值范围0至500人之间,②时点指标,③总和运算。
3.统计数据分类的描述
通过数据分类的描述,结合基础数据库语义,能够反应上述第二个方面的约束条件,包括:
(1)分类名称、分类值
(2)以树形方式表示各维间的层次关系
“A ”C“B”,表示A和B是父子关系,且A与B是一对多的关系,即:B维的一个分类流只能与A维的唯一一个分类值组合。
“A”X“B”,表示A和B是同辈关系,且A与B是多对多的关系。即:B维任何一个分类值都可以与A维的任何一个分类值组合。
例如,例1中的统计数据分类可以描述为:①“研究方向”:[研究方向一,研究方向二];“年份”:[1997,1998,1999,2000];②“研究方向”X“年份”。
为充分阐明统计数据各维间的关系,再看下列两个表达式:“地区 ”C“代理商”,表示:一个代理商只能代理一个地区的业务;“地区”X“代理商”表示:一个代理商可以代理多个地区的业务。
四、结束语
OLAP联机分析处理技术是使用极为广泛的一种数据挖掘技术,当运用该技术对独特的统计数据群进行分析时,可能会得到一些错误的计算结果和分析结论。因此,在实际统计部门的OLAP分析中,应明确问题的所在并予以充分重视和必要的技术保障,使OLAP灵活强大的分析功能得以充分展现和实施。我们在综合统计数据库应用平台课题的研制中使用上述技术,取得了很好的效果。
(本文不涉密)
责任编辑:
特别推荐





 |
站点信息
- 运营主体:中国信息化周报
- 商务合作:赵瑞华 010-88559646
- 微信公众号:扫描二维码,关注我们
