您现在的位置是:首页 > IT基础架构 > 软件与服务 >
数据挖掘流程中数据准备的探讨
摘要数据挖掘是一个应用统计学和人工智能等算法进行知识发现的过程。数据挖掘需要从庞大的数据集或数据库中提炼有用的信息,因而就产生了一个问题,如何为数据挖掘准备一个有效的数据集合,以提高效率,这是本文讨论的关键。...
由于计算机技术的进步以及由此延伸而来的数据库技术和计算机网络的广泛应用,加上使用先进的自动数据生成和采集工具,我们已经积累了而且还正在积累包含G字节或者甚至是T字节的庞大数据集。这些堆积如山的数据包含了可能很有价值的信息,问题是如何把这些有价值的信息从包围它的大量枯燥的数字中提取出来,从而使数据拥有者可以从中获得收益,这就是数据挖掘所要做的通过筛分这些数据库对它们进行总结并寻找其中的潜在的模式。而在数据挖掘的过程中,不可避免地会涉及到多个数据源,本文的目的,就是探讨数据挖掘的流程,重点讨论这一过程中的数据准备问题,使用数据融合技术,使数据挖掘能有一个单一的尽量充分完整的数据集合。
2 数据挖掘的流程
数据挖掘的流程包括以下几个内容:定义目标、数据处理、建立模型、评价模型。我们在以下的内容中重点讨论数据挖掘中的数据准备环节:
2.1 定义目标
数据准备的第一步是定义目标,首先要明确你要去度量或预测什么。数据挖掘是面向商业应用的,在数据挖掘的过程中,都应该定义一个或者多个商业目标,否则数据挖掘可能漫无目的。根据特定的目标选择或准备数据,建立不同的模型,同时可以评价数据挖掘的效果。
2.2 数据处理
有些人认为,在现代社会,呈指数增长的信息量能为数据挖掘提供巨大的机会,但是在实践中,这些信息并不是都能直接获取。正是由于信息的这种增长速度,这些资源被分割成更小的部分,这就形成了对数据挖掘更加广泛地应用及更成功探索的一个障碍,这就要求我们在数据挖掘之前进行数据处理。
1)数据过滤:这一步可以确保收集的数据符号分析的需要。数据挖掘的前提是高质量的数据,如果数据有缺陷的话即使最先进的数据挖掘工具也不会有结果。
2)数据预处理:这一步骤应确保原始数据和输入标准一致。数据挖掘所需要的数据可能在不同的数据库中,需要集成和合并数据到单一的数据库,并协调来自多个数据源的数据在数值上的差异,使数据属性标准化,同时,还要去除重复数据。因此,我们在这里介绍一种为数据挖掘做数据准备的技术,数据融合。
数据融合是一个通过将不同数据源的信息相结合,浓缩数据集的过程,能为数据挖掘提供一个单一的、丰富的数据集,从而通过提供更多的数据以供挖掘,促使数据挖掘者发现有价值的模式。
数据融合工程是很复杂的一个过程,这不是一个单一的数据集,而有几个不同的数据资源被包含在其中。我们先来介绍一下数据融合的概念,假设存在两个数据集,可以看成是数据库中不相关的两张表,将被扩展的数据集,我们将它称之为容纳集A,要作为额外的信息被加入的,称之为施与集B。假设这两个集合共享一些变量,这些共享的变量被称为公共变量X。数据融合过程会将这些变量加入容纳集A中,这些被加入的变量称为融合变量Z,而融合后的数据我们将它称为融合数据集C。独立的变量是那些仅仅出现在两个集合之一中的变量,例如A中的, B中的Y’,进行数据融合开始,首先检查各自数据中的变量,找出公共的变量及独立变量,用这样的公式能够说明:A(Y,X)+B(Y’,X)=C(Y,X,Y’)。
数据融合过程如下图:
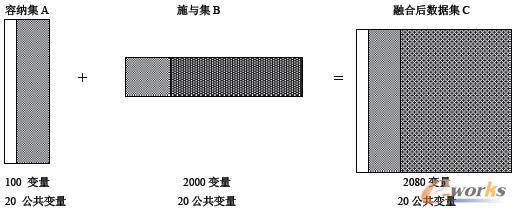
图1 数据融合过程
通过这样一个融合过程,减少最终数据集合中变量的个数,实际是去除两个集合的公共变量,减少重复变量,将各个分离的集合融合成一个集合,数据融合最终目的是将来源于不同数据集的资料融合,实际上是为数据挖掘建立一个单一的数据集,从减少分析变量类型和数量的角度,提高了数据挖掘的效率。
3)数据分析:分析数据和理解数据的特征是保证创建良好的预测模型的第一步。必须对预处理后的数据形成初步的认识,其总包括寻找出最大值、最小值,以及处理数据错误、孤立点和缺失值,了解数据分布状况等。
4)数据准备:这是建模前数据处理的最后一步。创建建模数据集之前,应该考虑是否要用采样来减小建模数据集的尺寸。从数据中选择一个子集或样本来建立模型,最后仔细检查与精化数据,转换变量,使之和选定用来建立模型的算法一致。
数据挖掘流程中还包含了另外两个环节:建立模型和评价模型。建立模型是指在多个可供选择的模型中寻找出最佳模型,初始模型可能没有发达到可以直接实现数据挖掘的的最终目的,需要多次反复。在寻找最佳模型过程中,如果发现问题,要修正正在使用的数据,设置修改问题的陈述。评价模型这个阶段是对数据挖掘阶段构建的模型质量进行评定。模型验证的标准方法是从预处理数据中随机抽取两个样本,一个校准样本用于构建模型,一个样本用于验证校准样本产生的模型。通常一个好的模型运用到验证样本中能得到较好的效果,如果效果很差,就需要重新构建模型。
3 结 论
数据挖掘最终的面向商业应用的,为了增强数据挖掘的效果,许多公司不断地收集、合并、净化数据,刚开始应用数据挖掘的公司则需要修补数据库,使访问和抽取更容易。要想使用好数据源,提高数据挖掘的效率最重要的一点是理解数据的本质及数据的聚集和管理方式。因此,在数据挖掘流程之中的数据准备过程就显得尤为重要了。
(本文不涉密)
责任编辑:
特别推荐





 |
站点信息
- 运营主体:中国信息化周报
- 商务合作:赵瑞华 010-88559646
- 微信公众号:扫描二维码,关注我们
