您现在的位置是:首页 > 大数据 >
百分点大数据技术团队:舆情平台架构实践与演进
摘要百分点舆情洞察系统(Mediaforce)是一款面向政企客户的舆情监测SaaS 产品,自2014年上线至今,已累计服务客户近万家,积累了逾20 PB的全网数据,通过构建丰富的上层应用,为客户提供精准、实时、全面、多维度的洞察服务。...
现代社会每天都有大量信息产生,抖音、小红书等自媒体的普及,不断丰富着人们表达看法、传播诉求、分享信息的渠道和形式。如何完成多源异构数据的收集和处理,挖掘海量信息中的价值,洞察事件背后的观点和情绪,是做好政府和企业舆情监测工作不可忽视的问题。
百分点舆情洞察系统(Mediaforce)是一款面向政企客户的舆情监测SaaS 产品,自2014年上线至今,已累计服务客户近万家,积累了逾20 PB的全网数据,通过构建丰富的上层应用,为客户提供精准、实时、全面、多维度的洞察服务。
本文从底层数据治理、上层应用架构,以及数据个性化和智能化角度,分享了大数据平台架构、AI平台架构和微服务架构在舆情产品上的实践。
一、平台架构简介
伴随着互联网内容形态的蓬勃发展,Mediaforce 平台数据量增长迅速,在产品创新和迭代过程中,自身平台架构也在不断的演进。
互联网舆情本质上是对互联网公开信息的采集、分析、研判,并产生业务价值,是一个价值数据挖掘的过程,我们覆盖了90%以上的网络公开数据,包含但不限于以下信源:
· 在线新闻、报刊、贴吧、博客、论坛、微博、微信、APP客户端;
· 电视、广播等;
· 社交自媒体:抖音、快手、小红书等。
百分点科技通过对以上数据进行存储、挖掘、可视化分析等一系列处理,最终为用户呈现多终端触达、一站式的舆情监测和价值分析平台。到目前为止,大体分为如下三个平台架构,对应职责如下:
大数据平台架构
· 数据共享:统一业务数据存储,结合业务实际场景对数据进行关联使用,避免数据重复存储,降低沟通成本;
· 服务共享:统一服务架构,避免服务孤岛,统一服务的访问入口和访问规则;
· 易于使用:通过平台服务和工具的形式暴露平台能力,屏蔽平台底层细节。
AI平台架构
· 数据层:以平台化能力应对数据收集、数据准备等繁重工作,同时结合业务,构建数据流转闭环;
· 深度学习平台层:实现多租户及弹性的资源分配、模型库扩展、可视化训练和调整、滚动更新等能力;
· 应用和工具层:借助Rest\Grpc模型开放能力,对接金融领域舆情、定制化行业标签、离线数据预测等场景。
微服务架构
· 拆分:按照业务垂直拆分和功能水平拆分的总原则,以及从业务侧尽量规避分布式事务等考虑;
· 云原生:减少微服务架构的运维成本,借助容器化技术,实现资源动态感知、扩缩容等特性。
二、大数据平台架构
百分点舆情洞察系统最初是通过自主构建IDC来支撑,IaaS层由单独的运维团队来进行维护。
大数据平台(IaaS层除外)分层如下:

测试中发现集群相对稳定,相对于单线程,多线程下的平均延迟高于1s也较少。在Elasticsearch6.0.0上进行相同的测试,其中平均延迟延迟高于1s占80%。
TiDB+Elasticsearch
TiDB 4.0版本已经是一款HTAP混合型分析引擎,将测试数据集限定为千万级,在测试中设置:tidb_hashagg_final_concurrency=20和tidb_hashagg_partial_concurrency = 20,平均耗时稳定在 8s~9s。由于聚合后的基数较大,压力都集中在TiDB侧,未能达到去ES的OLAP的场景。更多信息请参照AskTUG:千万级数据group by性能调优[1]。随着TiDB 5.0发布,TiFlash已经不仅仅是一个列式存储引擎这么简单。TiFlash引入了MPP模式,使得整个TiFlash从单纯的存储节点升级成为一个全功能的分析引擎。
[1] https://asktug.com/t/topic/68474/1
DorisDB+Elasticsearch
Mpp引擎列式存储设计对于数据更新是极其不友好的。借助DorisDB的更新模型引擎,内部通过版本号,可以支持大规模的数据实时更新,当然在查询时需要完成多版合并。同时Doris-On-ES将Doris的分布式查询规划能力和ES(Elasticsearch)的全文检索能力相结合,提供更完善的OLAP分析场景解决方案。目前Doris On ES不支持聚合操作如sum,avg, min/max 等下推,计算方式是批量流式的从ES获取所有满足条件的文档,然后在Doris中进行计算。在测试场场景下,性能是可以满足OLAP场景。实践中发现,由于自建IDC机器较为老旧,无法支持SIMD指令,致使无法安装DorisDB。
在目前的业务场景下,百分点科技最终选择单一的Elasticsearch来作为数据集市层的存储和计算引擎。后续如果数据集市有更大的数据量以及业务低延迟的OLAP查询场景,还是会考虑结合MPP查询引擎来满足业务的扩展。
3.2 数据仓库层
在之前的很长一段时间内,Elasticsearch Cluster承担了大量数仓的职能。通过多集群进行冷热数据隔离。在本次调整中,百分点科技借助索引生命周期管理(ILM)和Hot\Warm架构来实现在一个集群中进行数据的管理。在实践中,我们将Elasticsearch率先升级到7.12.0,以满足向量化检索等更多场景。
3.3 源数据层
之前会将采集的数据存储至kafka,作为数据传输中转。但kafka一般存储的时间周期较短,且功能单一。因此需要一套统一的存储计算平台,需要满足如下要求:
· 全量的离线数据是通过ES-Hadoop进行按天备份,后续的变更就无法做到同步,复用性、灵活性较差;
· 图片、音视频等非结构化数据的接入,需要方便与上层机器学习应用深度融合;
· 辅助数据仓库,构建数据集市,保证实时性。
在最新的架构中,百分点科技将数据先入湖,构建ODS,辅助构建上层DW和DM。关于Data Lake,最终选取Hudi作为源数据层存储计算方案,并做了以下尝试:
Iceberg
Iceberg工程架构具有极高的抽象,可以与各种引擎无缝融合。字符串模糊匹配是一种重要场景,测试中遇到以下问题:如果某个字段存储为空字符串,在匹配中就会出现异常:java.lang.IllegalArgumentException: Truncate length should be positive[2]。另外就是查询对Stream相关支持还处于开发阶段,对于增量数据处理只能以Java Api方式实现。
[2] https://github.com/apache/iceberg/issues/2065
Hudi
Hudi显得尤为成熟,但是与 Spark 引擎绑定的较为紧密。在Hudi 0.6中对底层代码进行抽象,以适配Flink等主流计算引擎。同时其完善的增量查询机制非常适合实时数据集市的构建。另外Hudi Table并不需要提前创建,可以在写入数据时自动创建,这也是区别于Iceberg的一个点。
Hudi的引入,为底层数据平台带来了ACID能力,并且提供较好实时性。特别是为数据集市实时数据构建带来便捷,提供可扩展性。目前的简易数据架构如下:

三、AI平台架构
在海量的文本数据上,利用丰富的数据挖掘、深度学习、人工智能算法,训练在线和离线语义模型,一站式挖掘满足客户需要的舆情分析需求。在这一历程中,大致分为两个阶段:
· 文本分析平台:将通用文本能力服务化;
· 深度学习建模平台:高效、易用、低门槛的模型定制开发平台。
在上述演进中,最主要的变化在于各行各业都已经积累了较多的高价值数据,并且越来越需要定制满足自己场景的个性化模型。下面主要从这两个阶段分别展开对应的工作。
文本分析平台
在舆情分析场景中,依赖于分词、词性、新词发现、命名实体、主体分类、文本聚类、关键词提取、自动摘要、文本去重、情感分析、内容转换(简繁、拼音)、自动纠错、自动补全、文档解析等各种功能。产品架构和数据流程如下:
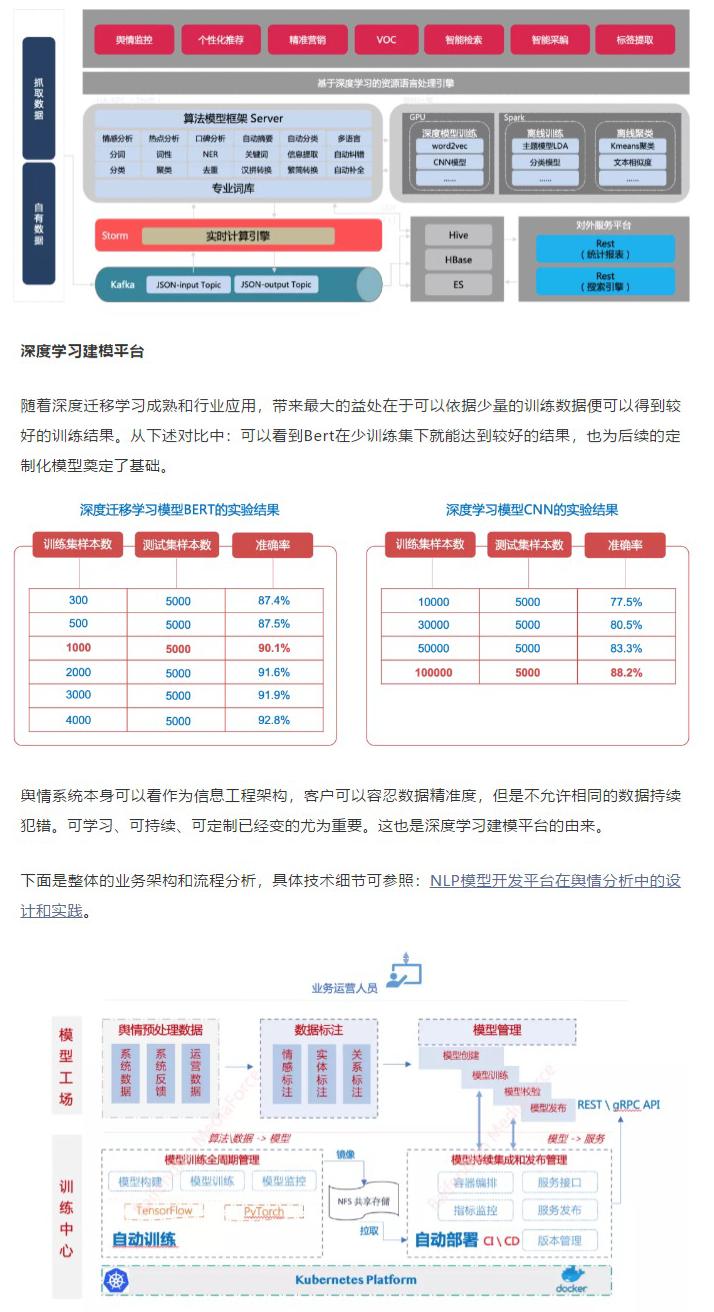
四、微服务架构下面对互联网架构演进之路进行总结如下,其中带颜色标记的为实践中的产物。

舆情业务应用系统从最核心几个业务功能,目前已经扩展至几十个业务模块。同时借助成熟的底层模块,快速沉淀出金融舆情、行业版等众多项目。大致经过以下三个阶段。
1. 单体架构
在业务初期,使用SpringBoot作为单体应用开发程序,可极大加快业务推进速度,简易架构如下: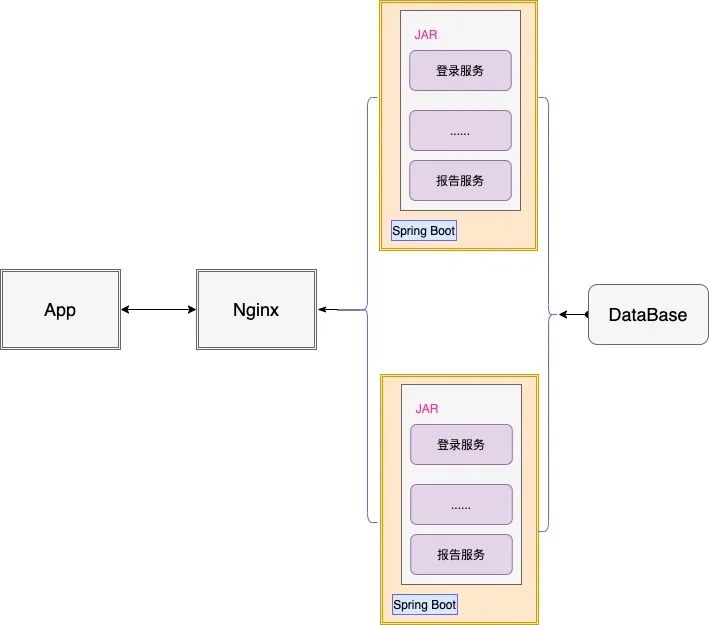
单体架构的优点在于其易开发、易测试、易部署、易扩展,但是业务耦合严重,也为业务扩展、服务治理带来了新的挑战。例如:登录服务和查询服务在一个单体应用中,因为查询服务是一个耗内存的操作,高峰时会引起FullGC,致使登录功能异常。
2. 微服务架构
微服务可以定义如下:· ⼀种架构⻛格,将单体应⽤划分成⼀组⼩的服务,服务之间相互协作,实现业务功能。每个服务运⾏在独⽴的进程中,服务间采⽤轻量级的通信机制协作(通常是HTTP/JSON);
· 每个服务围绕业务能⼒进⾏构建,并且能够通过⾃动化机制独⽴地部署;
· 很少有集中式的服务管理,每个服务可以使⽤不同的语⾔开发,使⽤不同的存储技术;
· 参考:https://www.martinfowler.com/articles/microservices.html。
随着业务扩展,业务耦合严重,开发效率低下、排查问题困难等。秉承业务维度垂直拆分和功能维度水平拆分的原则,同时尽量避免分布式事务等复杂度问题。拆分后架构图如下:

微服务拆分功效:
· 业务逻辑层:拆分后服务模块30+;
· 监控体系建立:日志监控、Metrics监控、调用链监控、告警系统、健康检查;
· 配置中心:灵活可视化的配置管理中心;
· 开发效率、团队协作能力提升。
3. 云原生架构
云原生包含了一组应用的模式,用于帮助企业快速,持续,可靠,规模化的交付业务软件。其特点如下:· 容器化封装:以容器为基础,提高整体开发水平,形成代码和组件重用,简化云原生应用程序的维护,在容器中运行应用程序和进程,并作为应用程序部署的独立单元,实现高水平资源隔离;
· 动态管理:通过集中式的编排调度系统来动态的管理和调度;
· 面向微服务:明确服务间的依赖,互相解耦。
借助百分点科技内部云平台,将微服务结构容器化封装,极大的降低了部署、运维的成本,也为服务的稳定性增加了保证机制。下面主要介绍一下云平台的基础概念和应用成效。
平台基础概念:
· 命名空间
管理常规用户的资源访问权限的中央载体,让一组用户组织和管理他们的内容,并与其它群体区隔开来。是用户账号的唯一公共URL访问地址。
· 容器
Docker容器为资源分割和调度的基本单位,封装整个软件运行时的环境,为开发者和管理员设计的,用于构建、发布和运行分布式应用平台。
· 镜像
含有启动Docker容器所需的文件系统结构及其内容,因此是启动一个Docker容器的基础。采用分层的结构构建。
· 项目
通过标签标识的多个版本的镜像组成。
· 构建
将输入参数转换为结果对象的过程;通常用于将输入参数或源代码转换为可运行的镜像从构建镜像创建Docker容器并将它们推送到集成的容器镜像仓库(Harbor)
S2I构建:通过注入应用源代码到Docker镜像并且组建新的Docker镜像来生成可运行的镜像新镜像中融合基础镜像和构建的源代码,并可搭配docker run命令使用。S2I支持递增构建,可重复利用以前的下载依赖项和过去构建的构件等。
· 服务
平台部署应用的最小单位,一个服务为一个功能单元,如mysql数据库服务。是定义容器实例的逻辑集合以及访问它们的策略,一个服务至少包含一个容器实例,服务通常用于为一组相似的容器提供永久IP。在内部,服务在被访问时实行负载均衡并代理到相应的支持容器实例,可以在服务中任意添加或者删除支持容器,而一直保持服务可用。
· 配额
在同一个命名空间内可以创建的最大对象资源数量,以及每个容器请求的计算/内存/存储资源。
· 高级编排
编排模板:描述可以参数化和处理一系列对象,生成的服务、构建配置和部署配置。可以为开发人员即时创建可部署的应用。
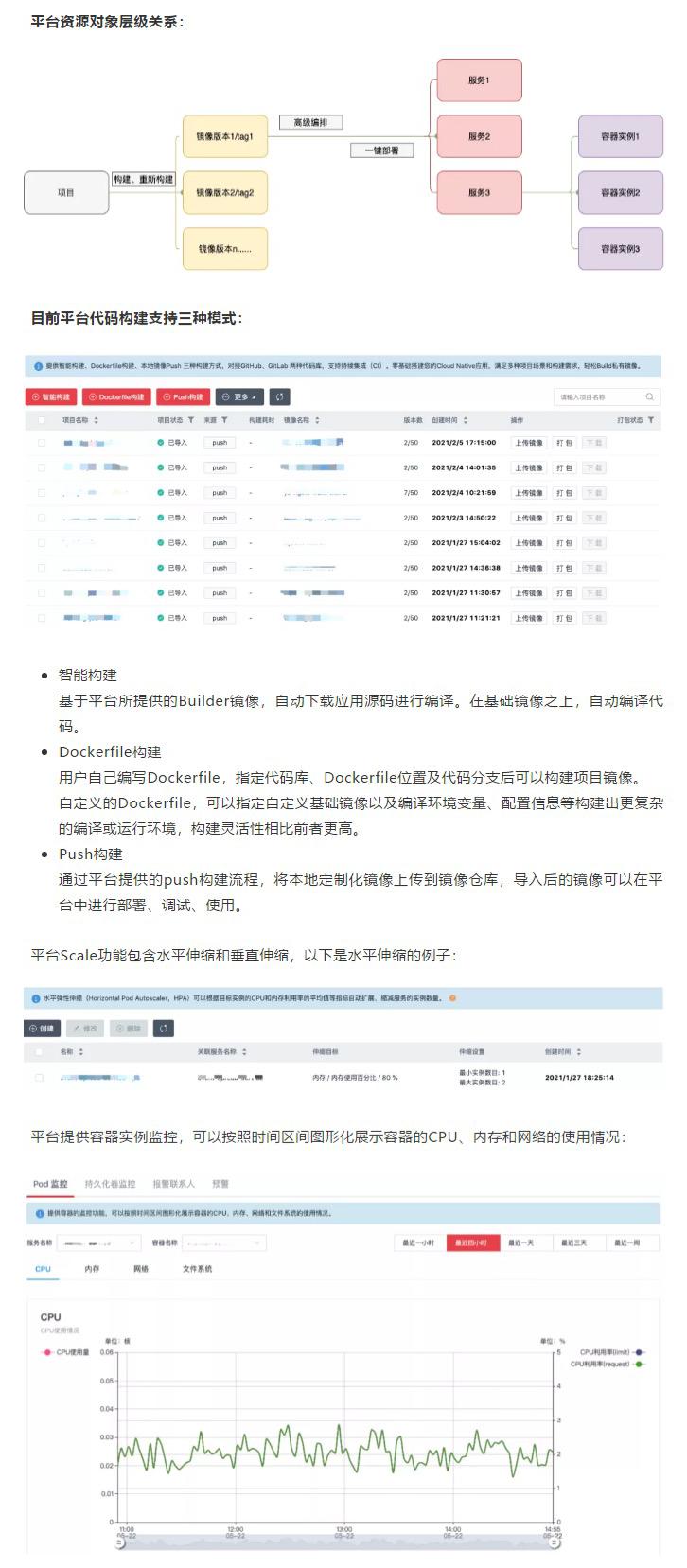
平台资源对象层级关系:
总结
企业SaaS一般是围绕获客、转化、留存这三个阶段展开,平台的易用性、数据的准确性和实时性等都是客户留存的核心要素。在多年的实践中,大数据架构以数据湖为ODS层,来保证对原始数据高效、灵活的处理,同时为其他业务线开放数据处理能力。AI平台架构提供一套端到端的闭环流水线,打造个性化、智能化的业务。微服务架构通过容器化,极大的降低维护成本,同时保证线上稳定性。随着SaaS产品矩阵的扩充,百分点科技在金融舆情、企业品牌监测等多个方向进行积极尝试,底层平台架构在业务的快速落地中起到了重要作用。
(本文不涉密)
责任编辑:杨光
特别推荐





 |
站点信息
- 运营主体:中国信息化周报
- 商务合作:赵瑞华 010-88559646
- 微信公众号:扫描二维码,关注我们
